大数据处理技术(一):数据管理的背景与演化 |
您所在的位置:网站首页 › power bi缺点 › 大数据处理技术(一):数据管理的背景与演化 |
大数据处理技术(一):数据管理的背景与演化
|
目录 一、数据管理--文件系统 二、数据管理--数据库 三、数据管理--Google在大数据层面引领发展 四、数据管理--NoSQL 五、数据管理--NewSQL 总结
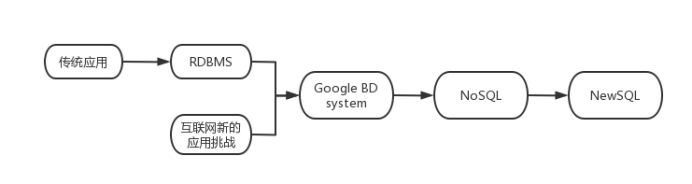
本学期在上《大数据处理技术》课程,在这里记录一下学习的过程。 用两张图来表示数据管理演化过程:
计算机系统如何管理数据?(以linux为例) 学习过计算机操作系统之后,我们可以知道,linux系统使用文件系统来管理数据。 通过将数据抽象成统一的文件,可以很方便的管理数据,但是这样的管理办法也有一些缺点: 1)通过编程的方式解决数据访问 数据的格式不同,参数不同,文件的访问接口不同,进行数据的访问过程相当麻烦。 2)查找的效率如何优化? 在文件中查找数据效率较慢,例如:在一篇文章中寻找某个单词,只能通过对文件进行遍历进行查找,而这种查询方式是比较缓慢的。 3)如何处理并发访问? 尽管OS文件系统提供了几种文件的共享方式,但是不可否认的是,对文件进行共享是一件比较麻烦的事情。 4)如何保证宕机时数据不会丢失? 在文件中写入数据,数据一般不会直接写入到磁盘中,而是写入到缓冲区之中,最后一起写入磁盘(原因是I/O操作的速度太慢,如果直接写入磁盘会耗费大量时间,这在操作系统中叫作“推迟写”),但是如果发生断电事故,缓冲区的数据都会丢失。 5)除此之外还有数据冗余、数据不一致、数据完整性、多操作的原子性、安全性等等问题 这就需要一种新的数据管理方式,也就是数据库(Database) 二、数据管理--数据库最先出现的数据库是关系型数据库(RDB),也就是采用了关系模型的数据库。 所谓的关系模型就是列(属性)、行(元组)、表(关系),我们通过关系代数对数据进行查找。 数据库的出现解决了上面文件管理系统没有解决的问题: 1)通过编程的方式解决数据访问 按Schema存储,通过SQL语句访问 2)查找的效率如何优化? 提供索引机制(主键索引,二级索引等) 3)如何处理并发访问? 提供并发访问的控制(事务的功能之一) 4)如何保证宕机时数据不会丢失? 持久化日志(事务的功能之一) 5)除此之外还有数据冗余、数据不一致、数据完整性、多操作的原子性、安全性等等问题 提供完整的ACID事务,函数依赖,范式,授权机制
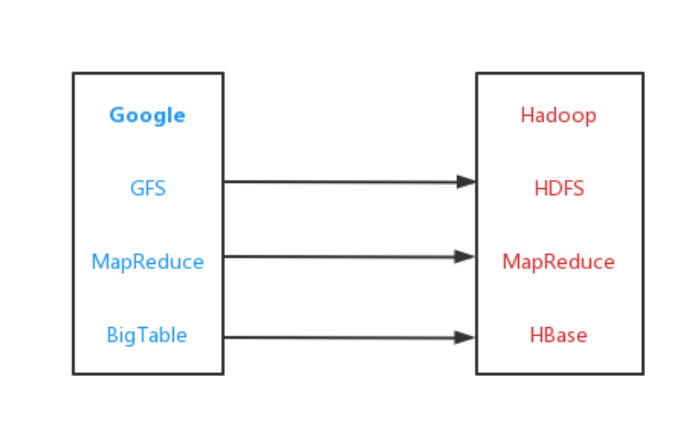
如上是单机数据库/OLTP数据库的出现以及发展,当今已经被广泛使用,例如:ORACLE DB2 MySQL PostgreSQL数据库 三、数据管理--Google在大数据层面引领发展由于移动互联网的出现以及移动应用的快速发展,无线互联的高速进化导致应用模式发生以下变化: 数据层面:数据的变化,大数据时代 数据量急剧增长 类型丰富多样 处理时效要求更高(ETL过程耗时较高) 系统层面:对数据系统的新需求 可扩展性 弹性 容错性 负载均衡 效率 对于新的挑战,Google做出了应对并引领大数据的发展,也就是现在所熟知的Google的三驾马车: GFS(分布式文件系统) 存储海量的互联网信息以供Google搜索引擎查找 MapReduce(在大量集群上简单的数据处理) 利用倒排索引对数据进行处理,所谓的倒排索引就是按照关键词(key)做排列,关键词所在文件作为排列结果(value),根据关键词词频确定关联性 正常的排列(查找关键词比较缓慢): 文件1关键词1,关键词2,关键词3文件2关键词2,关键词3文件3关键词1,关键词3而倒排索引如下(加快了查询速率): 关键词1文件1,文件3关键词2文件1,文件2关键词3文件1,文件2,文件3Bigtable(分布式文件系统上的分布式索引) 数据更新后,通过建立索引加速查找更新数据 然而Google的“三驾马车”是闭源的,无法借鉴源代码,但是Hadoop按照Google的实现方法,复现了这三驾马车
为什么SQL会遭到众多的“抵制”呢? 主要原因就在于SQL中对于事务的一致性、安全性等要求过高,导致占用了大量的资源在对事务进行加锁上,而花费在执行事务本身的时间却非常少。 因此NoSQL应运而生,NoSQL的特点如下: 开源、运行在廉价服务器集群上 高可扩展、高可用、容错的分布式架构 降低对强一致性的要求(放松强事务语义)只考虑最终一致性 放松或放弃对关系模型的强制要求 不强制要求使用SQL作为查询语言 采用更灵活的其他数据模型 这些其他的数据模型如下: 键值数据模型 redis 列族模型(column family)HBase 图模型 Neo4j 面向文档模型(半结构化)MongoDB 五、数据管理--NewSQL既然NoSQL有好处,为什么Google要推出NewSQL--Spanner呢? 因为NoSQL给应用开发带来了很多麻烦,比如,在应用层面需要进行更多的限制来保证操作安全和事务一致,导致应用层面的编程更加复杂。 换句话说就是,NoSQL并没有解决问题,而是将问题转移到了上层解决,这就给程序员带来了很多麻烦。 因此Google推出的NewSQL改善了这一问题: NewSQL Spanner分布式 支持完整的事务语义 一句话来讲就是 NewSQL=Scale-out(NoSQL)+transaction 总结再看这一张图就有了更深刻的理解: A history of database in no-tation 1970: NoSQL = We have no SQL1980: NoSQL = Know SQL2000: NoSQL = No SQL!2005: NoSQL = Not only SQL2013: NoSQL = No,SQL!
|
【本文地址】
今日新闻 |
推荐新闻 |